


本文结构
在服务端应用程序中,我们往往会通过事务处理来保证数据一致性(Data Consistency),例如:当用户从库存中取走了一定数量的物品,这些物品会体现在用户的提货单上,与此同时,库存中物品的数量也应该减少。如果在这个过程中无法保证数据的一致性,那么就有可能出现用户没有成功取走物品,而库存中的物品数量却减少了;或者用户成功取走了物品,而库存中的物品数量却没有变化。前者导致物品总量比实际少了一些,而后者又导致物品总量比实际多了,这样的问题就是数据一致性问题。为了保证应用程序不会出现这类问题,我们通常会使用数据库事务。单说数据库事务就有很多相关的知识,但这都不是这里打算深入讨论的内容。我们会着重介绍一下微服务架构下跨服务事务的实现以及与之相关的Saga体系结构模式,不过在此之前,还是有必要回顾一下事务处理的一些解决方案。
本地事务
本地事务通常会在同一个资源管理器(Resource Manager)上完成,最为常见的例子就是在同一个数据库上操作多张数据表,在这些操作完成之后,数据表的变更同时成功或者同时失败。例如,下面的C#代码会在一个本地事务中同时更新两张数据表:
using var connection = new SqlConnection("Server=localhost;Database=sql_sample;uid=sa;password=Pass@w0rd");
using var transaction = connection.BeginTransaction();
try
{
var updateUserCommand = new SqlCommand(
"UPDATE [dbo].[Users] SET [Credit]=10 WHERE [UserID]=\"abc\"",
connection,
transaction);
updateUserCommand.ExecuteNonQuery();
var updateInventoryCommand = new SqlCommand(
"UPDATE [dbo].[Inventory] SET [AMOUNT]=10 WHERE [ID]=\"def\"",
connection,
transaction);
updateInventoryCommand.ExecuteNonQuery();
transaction.Commit();
}
catch (Exception ex)
{
Console.WriteLine(ex);
transaction.Rollback();
}
代码中SqlTransaction能够保证,对于Users表和Inventory表的更新要么同时成功,要么同时失败。这个本地事务是在SQL Server的资源管理器上执行,因此,本地事务的效率是比较高的。
在微服务架构中,我们往往会选择Database-per-Service的设计,这样做的好处是能够获得比较好的数据隔离性,而且不同的服务可以根据本身的特点选择不同的数据存储方案。因此,就单个服务而言,实现本地事务是比较容易的事情,它能够很好地满足服务本身的业务需求,也能够很好地保证数据的一致性。然而很明显,本地事务无法保证跨服务的数据一致性。
分布式事务
分布式事务往往会横跨多个资源管理器(Resource Manager,RM),并由分布式事务协调器(Distributed Transaction Coordinator,DTC)负责事务协调。分布式事务通常基于两段提交协议(Two-phase Commit, 2PC)实现:事务提交分两个阶段进行,在第一阶段(准备阶段)中,2PC协议需要确保DTC已经获得了所有来自RM的提交反馈信息,对于每个RM,DTC都需要明确知道它是否可以成功完成其本地事务,或者无法完成。就RM而言,在这一阶段会尝试提交其本地事务,如果能够成功提交,则向DTC报告“可以提交”的状态,否则报告“无法提交”的状态。DTC在收集了所有参与者RM的状态后,如果全部为“可以提交”,则启动第二阶段(提交阶段),通知所有RM完成正式提交;但只要有一个RM报告“无法提交”,则DTC会通知其它的RM取消提交操作。
一个成功的2PC提交的过程大致可以用下面的顺序图来表示:
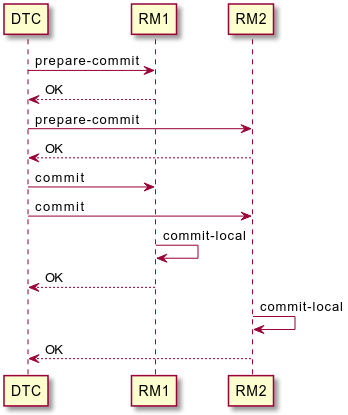
此外,三段提交协议(Three-phase commit, 3PC)也是实现分布式事务的一种模式,与2PC相比,3PC主要是为了解决DTC或者RM出现故障的情形,它将2PC中的第一阶段(准备阶段)进行了细分,将RM分为了Awaiting和pre-commit两种状态。总的来说,3PC和2PC过程大致相同,可以参考这篇文章进一步了解,在此就不多说了。
从 2.0版本开始,.NET Framework引入了一个非常方便的类:TransactionScope,这个类能够辅助完成分布式事务处理,比如,下面的伪代码能够实现跨SQL Server服务器的事务处理:
using (TransactionScope scope = new TransactionScope())
{
using (con = new SqlConnection(conString1))
{
con.Open();
// Do Operation 1
// Do Operation 2
//...
}
using (con = new SqlConnection(conString2))
{
con.Open();
// Do Operation 1
// Do Operation 2
//...
}
scope.Complete();
}
然而,获得如此的便捷需要付出一定的成本:首先,跨数据库的事务处理效率是非常低的;其次,不是所有的数据库驱动都能够支持TransactionScope,并且,上面的代码需要执行成功,就需要确保Windows操作系统中的Distributed Transaction Coordinator服务是处于启动状态,而且应用程序与该服务间的通讯不能中断。

图:Microsoft Distributed Transaction Coordinator服务
然而在微服务架构中,无法通过分布式事务来保证数据的一致性,原因大致有如下几个方面:
- 2PC/3PC协议是阻塞式协议,其本身的特点使得分布式事务协调器成为了整个体系中的单点,一旦DTC发生错误,容易导致RM长期处于等待状态,资源得不到释放,从而造成服务不可用。或者更进一步,如果在提交阶段,其中某个服务真的提交失败了,那又如何维持各服务间状态的一致性?解决这样的问题并不是不可能,但是成本会比较大,而且,这还不是微服务架构下实现2PC/3PC协议的唯一弊端
- 基于2PC/3PC协议的分布式事务处理比较低效,由于它是阻塞式的,所以服务本身需要完成提交或者回滚之后才能继续处理其它的事务,在微服务环境中,一次这样的阻塞可能会影响到很多的服务实例
- 不是所有的数据库或者基础结构设施都能够支持2PC/3PC协议,应该说绝大部分不支持。我所用过的可以支持分布式事务的基础结构设施包括Microsoft SQL Server数据库、Oracle数据库以及微软的MSMQ,因此,在技术选型上是有一定限制的:如果你的微服务所采用的数据存储/数据传输技术不是这些,那么就很难实现分布式事务。此外,分布式事务协调器本身也有很多限制,比如上面提到的MSDTC就只能在Windows Server上运行
- 这种分布式事务处理方式打破了微服务架构的设计原则:Database-per-service的设计要求微服务之间不能互相访问对方的数据库,而DTC的存在,使得数据库实现细节不得不被暴露出来,否则DTC无法完成跨数据库的事务协调
Saga模式:跨服务的事务处理
在微服务架构中,事务处理往往会横跨多个服务,这就难免会需要依赖于服务间的通信机制。微服务间的通信分同步和异步,而异步通信才是更为推荐的方案:在设计微服务架构时,应该尽可能地选择异步方式来实现服务间通信,这样才能更好地实现服务间解耦。就事务处理而言,由于它并不是一个瞬时操作,而是一个长时运行的任务(long-running process),因此更适合采用异步方式来完成。Saga模式所解决的问题就是这种基于异步消息机制的跨服务事务处理,它的基本过程是,每个微服务自己处理本地事务,然后根据处理结果向消息队列派发消息以便整个事务能够进行下一步的处理,与此同时,微服务还会侦听来自于其它微服务的消息,来决定自己是否需要进行事务补偿(Compensation)。当一个Saga事务被启动后,它会一步一步地执行其中的每一个步骤(Saga Step)。在每一个步骤中,有且仅有一个微服务实例的参与者负责其本地事务的执行,当所有的步骤全部成功完成后,Saga事务也就成功提交了。当然,如果其中有某个步骤执行失败,那么之前成功的本地事务就应该回滚,否则无法保证数据一致性。由于此刻已成功的本地事务已经无法回滚,所以,在Saga模式中,一般都会通过补偿操作来实现本地事务回滚的效果。整个流程大致可以使用下面的流程图表示:

一般会有两种方式来实现Saga模式:编排式和协调式。
编排式(Choreography)
编排式Saga实现中,会将每个步骤分散到各个微服务中,通过事件消息的相关性将这些Saga步骤串联起来,“编排”出一个Saga事务处理流程。例如:购物车微服务发出一个“创建销售订单”的消息,订单微服务侦听到这个消息并创建销售订单,库存微服务则在侦听到这个消息后,检查库存状态,如果库存不足,则发出一个“库存状态检查失败”的消息,然后订单微服务获得这个消息后,执行一个补偿事务,将订单状态标记为“失效”,购物车微服务则执行它的补偿事务,将当前购物车中的信息恢复到创建订单之前的样子。整个过程中,微服务之间互通信息,没有第三方的组件参与协调它们之间的协作关系,因此,这种实现方式被称作“编排式”。下面的示意图表示了这种编排式Saga的实现:

编排式实现有如下优点:
- 实现相对比较简单,尤其是当涉及的微服务个数并不多的时候,编排式实现比较简单明了
- 由于不需要依赖于第三方组件进行协调,所以不存在额外的部署和维护成本
但也有一些缺点:
- 当事务过程比较复杂时,往往一个Saga事务会包括多个步骤,编排式实现会使得整个事务处理过程变得错综复杂难于理解和维护
- 由于没有协调组件,消息来来回回容易造成混乱,甚至出现消息间互相影响循环处理的情况(比如A发消息给B,B处理完消息后又发消息给A,如此反复不断)
- 测试和排错变得复杂:你需要启动所有的微服务才能够调试或者测试某个Saga步骤
协调式(Orchestration)
协调式Saga实现中,会有一个协调器的角色来负责协调Saga的每一个步骤,协调器与各微服务之间也是通过消息队列进行通信,因此,它也是基于异步消息机制的。下面的示意图表示了协调式Saga的实现:
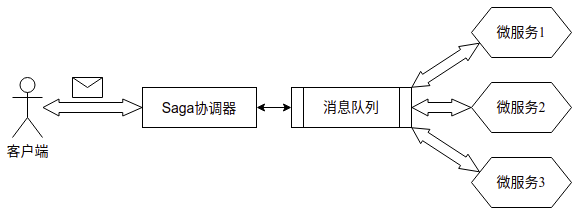
协调式Saga实现有如下这些优点:
- 对于过程比较复杂的Saga事务,协调式比编排式的实现更加清晰,不会出现消息混乱的情况
- 从单个微服务的角度,它无需关心在自己参与了Saga事务之后,应该如何协作以便Saga事务能够继续往下走,它只需要对自己所处理的Saga事件(Saga Events)完成应答即可,因此,协调式Saga能够更好地实现微服务的关注点分离(Separation of Concerns)
- 对于Saga事务流的控制更加简单,对于消息的收发和处理的调试也相对比较容易
当然,也有缺点:
- 由于需要额外引入一个协调器,所以结构上要比编排式更为复杂
对于编排式与协调式的优缺点,也有一些观点认为,协调式中的协调器部分会有单点失败的可能性,其实在微服务的体系中,如果设计上在这部分多加考虑,是可以避免这样的问题的,例如,可以利用消息队列的机制,保证Saga应答事件被、且仅被处理一次,那么,即使有多个协调器实例在运行,也能够保证Saga能够正确执行,在这种情况下,单个协调器发生故障无法正常工作也不会影响整个Saga事务的处理。
相比之下,我更倾向采用协调式的实现,一方面它能够分离关注点,使得Saga模式的实现变得更为优雅;另一方面,比较容易从实现中抽取出一套特定的框架,进而重用于不同的项目中。
接下来,我们通过一个简单的案例,来了解一下整个Saga体系的设计和实现。
案例:订单业务下Saga的简单实现
我们选择购物网站的下订单的流程来介绍Saga的实现。为了简化问题,我们将下订单的流程进行简化,并且省去了很多额外的业务处理部分(比如客户账户可用额度应该属于客户会员管理微服务,并且额度的增加和扣除都有一定的业务逻辑,这里我们就简单地将它归为客户信息微服务了),因此,不要太过纠结这样的业务流程是否合理。现假设有这样的业务场景:
- 客户通过网站的购物车系统下订单(Sales Order)
- 购物车微服务启动下订单的流程,在这个过程中:
- 首先,会通知订单微服务,需要创建一个订单,此时订单状态为Created
- 然后,客户信息微服务校验当前客户账户是否合法
- 接下来,客户信息微服务预留(扣除)客户账户的额度
- 最后,库存微服务预留(扣除)订单中商品的数量
- 这个过程中任何一步发生错误,都需要通知已执行的步骤,以便回滚已经更改的数据,保证数据一致性。比如,在预留客户账户额度的时候如果失败,则需要将订单状态置为Aborted,表示该订单因某些原因不得不取消
下面,我们基于这样的业务场景,简单地做些设计与实现。
总体设计
通过简单的分析,可以得知:
- 整个事务的完成需要涉及4个不同的微服务:购物车微服务、订单微服务、客户信息微服务和库存微服务
- 在不同的Saga事务步骤中,有些微服务的操作是有对应的补偿操作的,目的是为了在Saga事务执行失败时,能够将其本地数据变更回滚到变更之前的状态;而有些微服务的操作是无需补偿操作的,比如校验客户账户是否合法
- 每个Saga事务步骤都会有这几个状态:等待执行(Awaiting)、正在执行(Started)、成功执行(Succeeded)、执行失败(Failed)、正在补偿(Compensating)、补偿完成(Compensated)以及取消(Cancelled)
- 依据每个Saga事务步骤的不同状态,Saga本身也是有状态的:已创建(Created)、正在执行(Started)、正在撤销(Aborting)、已经撤销(Aborted)和成功完成(Completed)
基于这样的分析,可以得到下面的设计指导:
- 一个Saga事务(下面简称Saga)由若干个Saga事务步骤组成
- Saga是有状态的,它的各个步骤也是,因此,Saga是需要被持久化的
- Saga的管理以及Saga事件的处理都需要有一个管理者负责协调,称之为Saga Manager
- Saga与各个微服务之间采用异步消息进行通信
于是,相关的UML类图大致如下:

有几点大致说明一下:
- IDataAccessObject是一个数据访问的接口,它提供了对某种数据库中的数据进行增删改查的功能。在我们的案例中,采用MongoDB的实现
- IEventPublisher是一个事件派发接口,它可以向消息队列派发消息。在我们的案例中,采用RabbitMQ的实现
- Saga Manager会使用IDataAccessObject实例来管理Saga的生命周期,也会使用IEventPublisher实例来派发Saga消息
- 当SagaEventHandler接收到来自各个微服务的响应事件时,它会通过Saga Manager读取对应的Saga,然后在Saga上进行状态转换,从而触发下一个Saga步骤(或者上一个Saga步骤的补偿事务)的执行
- Saga维护本身及其各个步骤的状态,每个Saga步骤会有两个待实现的抽象方法,用来返回事务消息的类型,以及补偿事务消息的类型
执行过程可以用下面的UML顺序图来表示:

上面的顺序图仅展示了一次由Saga事件触发的状态转换过程,在这个过程中,难点就是Saga对象在得到当前Saga事件时,是如何完成状态转换,并产生下一步骤所对应的Saga事件的。下面就进行一些简单的介绍。
详细设计:Saga事件处理与状态转换
在SagaManager创建了Saga之后,会调用StartAsync方法,将第一个Saga Step的Saga事件发送到消息队列,之后,SagaManager会侦听自己的消息队列以便获得来自不同微服务的处理反馈消息。在这个Saga反馈消息事件的处理逻辑中,事件处理器会根据反馈消息事件中所附带的SagaId,通过SagaManager读取Saga实例,然后执行状态转换。例如,下面的代码就是在Saga反馈消息事件处理逻辑中,完成了Saga的状态转换:
class SagaEventHandler : IEventHandler<SagaEvent>
{
private readonly SagaManager _sagaManager;
public SagaEventHandler(SagaManager sagaManager)
{
_sagaManager = sagaManager;
}
public async Task<bool> HandleAsync(SagaEvent @event, CancellationToken cancellationToken = default)
{
await _sagaManager.TransitAsync(@event, cancellationToken);
return true;
}
}
在TransitAsync方法中,Saga通过对已接收到的反馈消息进行状态转换,并发出下一个Saga Step的消息:
public async Task TransitAsync(SagaEvent sagaEvent, CancellationToken cancellationToken = default)
{
Console.WriteLine($"{sagaEvent.EventType} - Succeeded: {sagaEvent.Succeeded}");
var saga = await _dao.GetByIdAsync<Saga>(sagaEvent.SagaId, cancellationToken);
var nextStepEvent = saga.ProcessEvent(sagaEvent);
if (nextStepEvent != null)
{
await _eventPublisher.PublishAsync(nextStepEvent, nextStepEvent.ServiceName, cancellationToken);
}
await _dao.UpdateByIdAsync(saga.Id, saga);
}
Saga的ProcessEvent的流程大致如下:
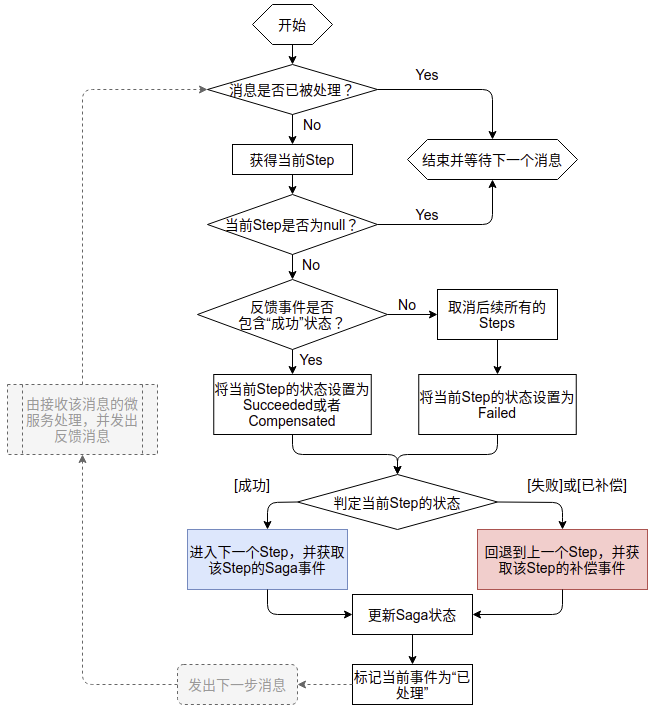
在上面的流程图中:
- 蓝色框和红色框中表示在这个节点上,会获得下一个Saga步骤或者上一个Saga步骤所产生的Saga事件,这个事件会被接下来的处理逻辑发送到消息队列中
- 蓝色框表示,当前Step已经执行成功,Saga的状态会转换到下一个步骤进行执行,并读取下一个步骤的Saga事件
- 红色框表示,当前Step已经执行成功,Saga的状态会转换到上一个步骤进行执行,并读取上一个步骤的补偿事件
- 灰色虚线框流程并不是ProcessEvent方法的主要职责,但为了保持流程的完整性,我将这部分用虚线补上
此外,值得一提的是,并不是所有的步骤都需要有补偿操作,比如,对于“客户信息微服务校验当前客户账户是否合法”这个步骤,如果其后续某个步骤失败,那么该步骤并不需要进行补偿,因为它本身没有产生任何领域对象状态的变更。对于这种情况,红色框中“回退到上一个Step”的操作就需要依次迭代之前的每个步骤,找到需要进行补偿的步骤为止。
就我们的例子而言,各个Saga步骤的定义如下:

对于“补偿事件类型”这一栏不为空的Saga步骤,它需要进行事务补偿,因此,当Saga执行失败并进行回溯时,需要在这些步骤上获取补偿事件并发送给对应的微服务,以完成事务补偿。
实现效果
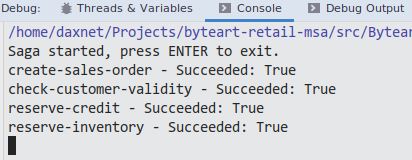
假设我们只允许客户最多预留1000元的账户额度,并且只能预留库存中不多于5000个商品,那么如果创建订单时,请求方给的参数没有超出这个范围,那么所有的微服务都应该应答“成功”消息,也就是对应的事件类型也应该为“成功”:
假设我们请求的库存预留数大于5000:
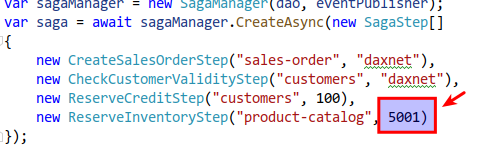
可以看到:当reserve-inventory事件的应答为false时,产生了两个补偿事件:compensate-reserve-credit和compensate-create-sales-order,并且这两个补偿事件的处理应答都为true:
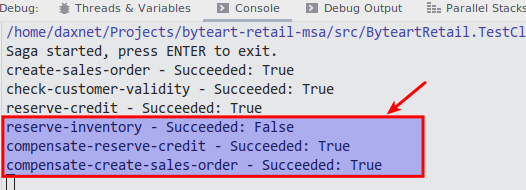
查询数据库状态,根据SagaStatus和SagaStepStatus两个枚举的值,Saga的状态为Aborted:
有关Saga的大致设计和实现就先介绍这些吧,其实内容还有很多,可以参考本文的案例代码:
https://github.com/daxnet/byteart-retail-msa
Saga框架相关的代码在此:
https://github.com/daxnet/byteart-retail-msa/tree/main/src/ByteartRetail.TestClients.Common/Sagas
CQRS中的Saga
顺便提一句,在CQRS体系结构模式中,Saga的实现有其自己的“职责”:
- Command接收命令,发出领域事件
- Saga接收领域事件,发出命令
如何理解?
- Command部分在接收到来自客户端的命令后,会操作领域模型对象,领域模型对象发生状态变化的结果,就是发出领域事件
- Saga在接收到领域事件之后,产生自身的状态转换,当达到某个状态时,又发出命令,从而影响领域模型
更多思考
实现Saga事务其实并不是那么容易,还有很多需要思考的内容,本文也没法全部涵盖,例如:
- 一个更为优雅的设计是使用有限状态机,使用Saga事件作为触发器,来完成Saga的状态转换,例如,使用MassTransit的Automatonymous框架
- 如何(或者是否需要)保证消息派发的顺序。在RabbitMQ中,发送到同一个Exchange,并由同一个RoutingKey指定的派发路由上的消息,可以保证其顺序性;再比如,Apache Kafka是可以保证消息的派发和接收顺序的。但是这些框架无法保证应用程序本身是按照消息接收的顺序进行处理。所以,微服务需要保证消息处理的幂等性
- 如何保证消息不会被遗漏,也就是如何保证消息至少被处理一次。可以采用Listen To Yourself模式(参考我之前的文章《ASP.NET Core Web API下事件驱动型架构的实现(五):在微服务中使用自我监听模式保证数据库更新与消息派发的可靠性》),也可以在微服务内部使用消息存储,确保未被派发消息不会丢失
- 如何保证补偿事务能够真正实现“补偿”。如果补偿不成功,也会导致数据不一致,无法实现最终一致性。可以在微服务处理补偿事务的时候,使用类似Retry或者熔断这样的机制,通过反复尝试来强制补偿成功。如果最终仍然不成功,则需要记录下来,等待后续手工补偿,比如,通过邮件通知的方式,由管理员进行处理
- 多个SagaManager实例同时运行时,如何保证Saga能被正确处理。通常可以让多个运行SagaManager的微服务实例同时侦听同一个消息队列,以便能够以轮询的形式处理反馈消息
以后有机会再慢慢分析吧。
总结
本文首先介绍了本地事务以及分布式事务,并通过微服务架构引入Saga体系结构模式,以实现跨服务的事务处理。然后通过一个简单的业务案例,介绍了Saga体系结构模式的整体设计和简单实现,并列举了一些遗留问题可供进一步思考和讨论。Saga的实现方式并非本文介绍的这一种,但本文介绍的方式还是相对比较简单易懂的。整个Saga的设计体系是可以抽象成一套开发框架的,以便隔离状态转换和事件派发的复杂度,让开发者更多地关注到业务实现上来。
Hi 晴阳
关于 协同式(Choreography)和 编排式(orchestration)的介绍,在文章中应该是弄反了。
reference:《微服务架构设计模式》 113页。
刘新宇
Hi 新宇:
解释上没有反,但是可能翻译的不确切。不同的地方翻译也不一样。Choreography在书里翻译为“协同式”,在微软官方翻译为“排版式”或“协调”。Orchestration在书里翻译为“编排式”,在微软官方翻译为“资源协调”。我查了字典,Choreography有编舞、编排的意思,所以我就自己给它取名为“编排式”了。当然为了防止我翻译不精确,我在文中还是保留英文的(至少表明我没有抄书。哈哈。)
感谢批评指正并分享你的见解!!